Troubleshooting¶
Getting support¶
All customers have access to a public Slack channel for support and collaboration.
Enterprise customers may also have an upgraded SLA for support tickets via email and access to a private Slack channel.
Billing and your plan¶
Change your credit card¶
Sometimes credit card limits or virtual cards are used on a subscription. To change the credit card used for your subscription, click here: My Orders.
Upgrade your plan¶
If you'd like to upgrade your plan for more concurrent builds, a higher level of support or anything else, you can do so via the Lemon Squeezy dashboard, the additional amount will be applied pro-rata.
The Actuated Dashboard¶
The first port of call should be the Actuated Dashboard where you can check the status of your agents and see the current queue of jobs.
For security reasons, an administrator for your GitHub Organisation will need to approve the Actuated Dashboard for access to your organisation before team members will be able to see any data. Send them the link for the dashboard, and have them specifically tick the checkbox for your organisation when logging in for the first time.
If you missed this step, have them head over to their Applications Settings page, click "Authorized OAuth Apps" and then "Actuated Dashboard". On this page, under "Organization access" they can click "Grant" for each of your organisations registered for actuated.
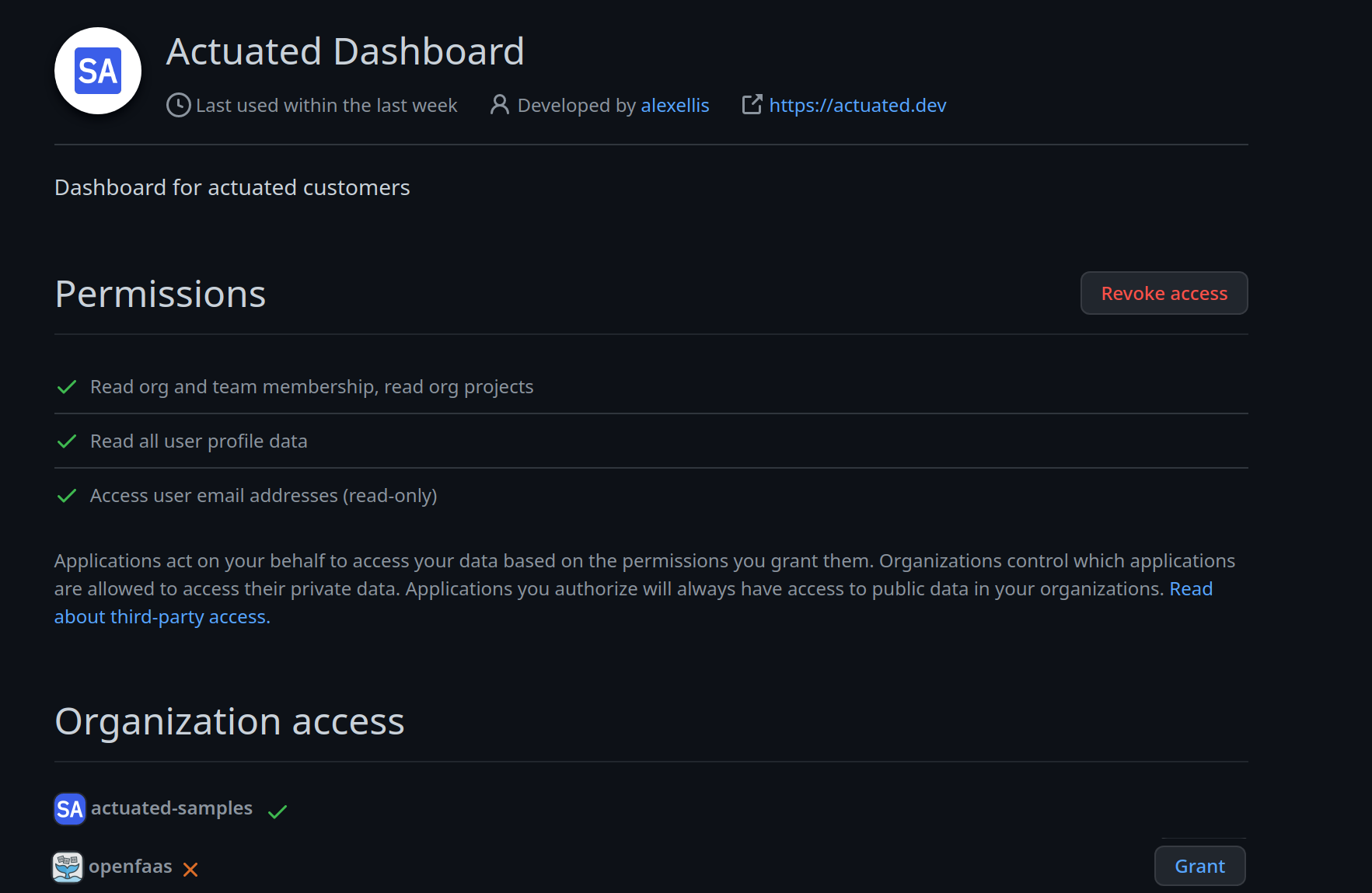
How to "Grant" access to the Dashboard.
Try a direct link here: Actuated Dashboard OAuth App
A job is stuck as "queued"¶
If you're using a private repo and the job is queued, let us know on Slack and we'll check the audit database to try and find out why.
To remotely check the logs of the actuated service on a host, run the following:
actuated-cli agent-logs --owner ORG --host HOST [--age 20m]
Or you can also check /var/log/actuated/ for log files, tail -n 20 /var/log/actuated/*.txt should show you any errors that may have occurred on any of the VM boot-ups or runner registrations. Or check sudo journalctl -u actuated to see what's happening within the actuated service.
Since 2022, the main GitHub service and/or Actions has had a high number of partial or full outages.
Check the GitHub Status Page to make sure GitHub is fully operational, and bear in mind that there could be an issue, even if it hasn't been shown on that page yet.
You can schedule additional VMs to launch, one per queued job with the CLI:
actuated-cli repair --org OWNER
This command should not be run multiple times without contacting support first.
You pull a lot of large images from the Docker Hub¶
As much as we like to make our images as small as possible, sometimes we just have to pull down either large artifacts or many smaller ones. It just can't be helped.
Since a MicroVM is a completely immutable environment, the pull needs to happen on each build, which is actually a good thing.
The pull speed can be dramatically improved by using a registry mirror on each agent:
You are running into rate limits when using container images from the Docker Hub¶
The Docker Hub implements stringent rate limits of 100 pulls per 6 hours, and 200 pulls per 6 hours if you log in. Pro accounts get an increased limit of 5000 pulls per 6 hours.
We've created simple instructions on how to set up a registry mirror to cache images on your Actuated Servers.
A job is running out of RAM or needs more cores¶
If you suspect a job is running out of RAM or would benefit from more vCPU, you can increase the allocation by changing the runs-on label, as follows:
-runs-on: actuated-8cpu-8gb
+runs-on: actuated-8cpu-16gb
You must set both RAM and vCPU at the same time, in the order of CPU (given in a whole number) followed by RAM (specified in GB)
For arm64 builds, the format follows the same convention: actuated-arm64-8cpu-16gb.'
Bear in mind that if you set the RAM higher than the default, this may result in fewer concurrent VMs being scheduled on a single server.
The maximum amount of vCPU that can be set for a single job is 32 vCPU, this is an implementation detail of Firecracker and may change in the future.
To find out exactly how many resources are required, see our blog post on right sizing with the vmmeter tool.
Disk space is running out for a job¶
The disk space allocated for jobs is 30GB by default, but this value can be increased. Contact the actuated team for instructions on how to do this.
A dedicated disk or partition should be allocated for your VMs, if that's not the case, contact us and we'll help you reconfigure the server.
Your agent has been offline or unavailable for a significant period of time¶
If your agent has been offline for a significant period of time, then our control plane will have disconnected it from its pool of available agents.
Contact us via Slack to have it reinstated.
You need to rotate the authentication token used for your agent¶
There should not be many reasons to rotate this token, however, if something's happened and it's been leaked or an employee has left the company, contact us via email for the update procedure.
You need to rotate your private/public keypair¶
Your private/public keypair is comparable to an SSH key, although it cannot be used to gain access to your agent via SSH.
If you need to rotate it for some reason, please contact us by email as soon as you can.
Your builds are slower than expected¶
- Check free disk space (
df -h) - Check for unattended updates/upgrades (
ps -ef | grep unattended-upgrades) and (ps -ef | grep apt)
If you're using spinning disks, then consider switching to SSDs. If you're already using SSDs, consider using PCIe/NVMe SSDs.
Finally, we do have another way to speed up microVMs by attaching another drive or partition to your host. Contact us for more information.